第一步:计算各组发病密度(发病率)
发病密度 = 发病数 / 观察人年(万人年)
•高水平组:I₁ = 90 / 6.0 = 15.0 例/万人年
•中水平组:I₂ = 136 / 6.2 ≈ 21.94 例/万人年
•低/无锻炼组:I₀ = 208 / 6.5 = 32.0 例/万人年
⭐ 注意单位!题目给的是”万人年”,结果必须写成”例/万人年”,单位错误扣1分!
第二步:以高水平组为暴露组,低/无组为对照组
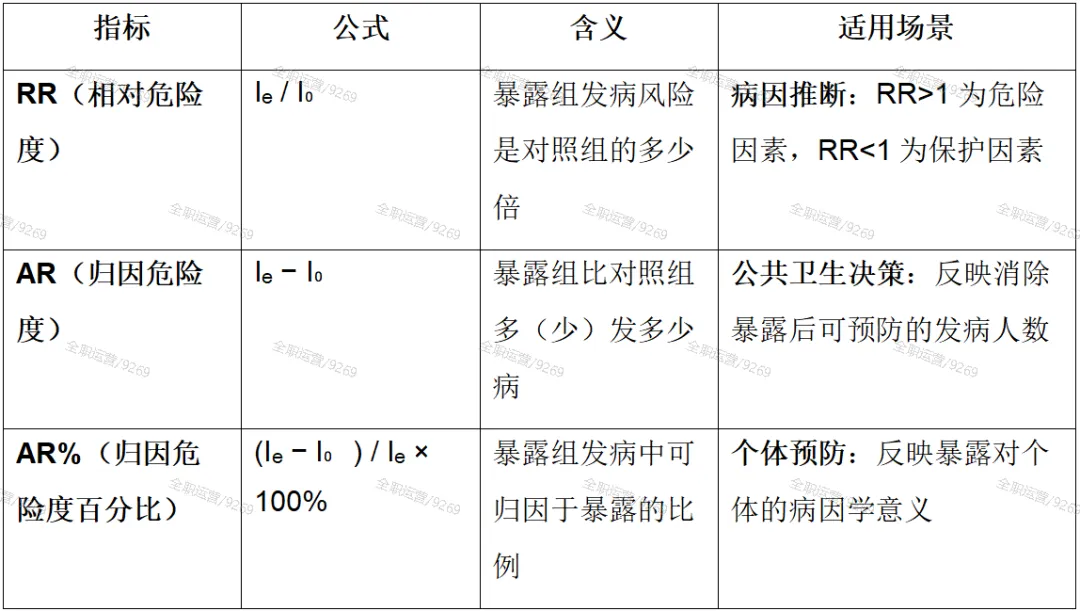
相对危险度 RR=I1/I0=15/32=0.46875
归因危险度AR=I1-I0=15-32--17例/万人年
归因危险度百分比AR%=(L1-10)/I1x100%=(-17)/15x100%≈-113.33%
第三步:以中水平组为暴露组,低/无组为对照组
RR=21.94/32≈0.686
AR=21.94-32=-10.06例/万人年
AR%-(21.94-32)/21.94x100%≈-45.85%
⚠️ 重要提示:本题RR<1,说明体育锻炼是保护因素!AR和AR%为负值,表示”归因于不锻炼的发病”,这是保护因素的正常表现,不要怀疑自己算错了!