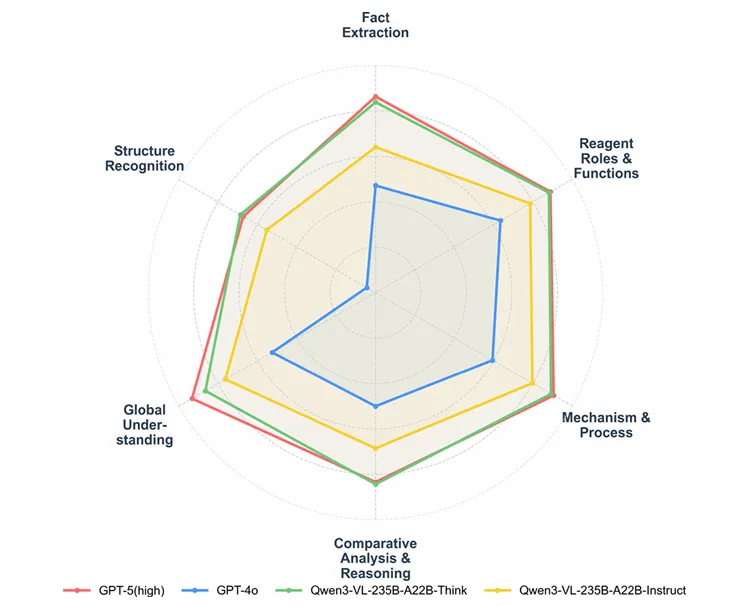
把六类任务拆开分析后,当前模型的能力边界变得十分清晰。
(1)事实提取:接近满分
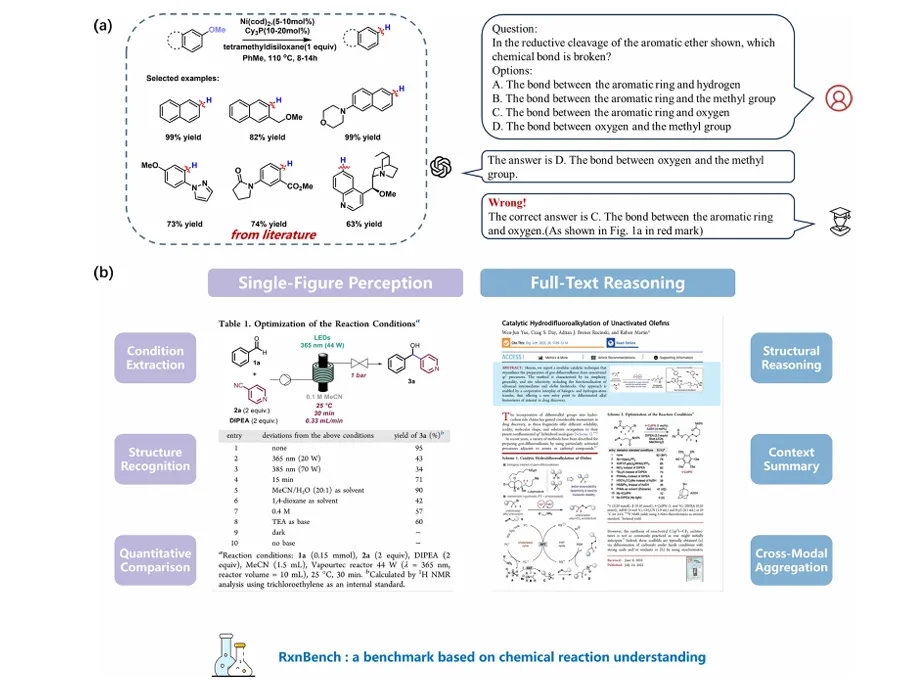
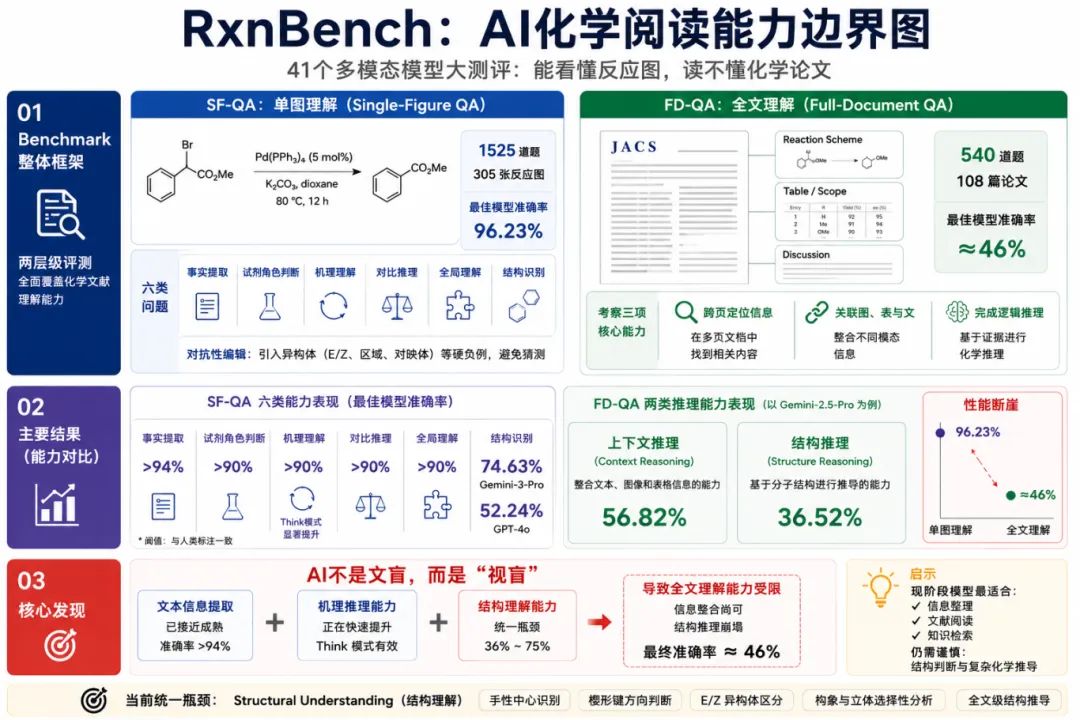
对于催化剂、温度、收率等直接标注在反应图中的信息,头部模型准确率普遍超过94%,Gemini-3-Pro-preview达到96.48%。只要答案明确写在图中,模型通常能够稳定识别。
(2)机理推理:Think模式带来真实增益
以Qwen3-VL系列为例,不开启Think时总成绩为85.84%,开启后提升至91.77%。增益主要集中在反应路径分析和过程推导任务中,说明推理链能够帮助模型更好地组织已有信息。
(3)结构识别:全员掉队
真正的问题出现在结构识别任务。Gemini-3-Pro-preview的准确率下降到74.63%,GPT-4o仅有52.24%。
模型能够准确识别“Pd(PPh₃)₄”这样的催化剂名称,却未必能够判断一个手性中心究竟是R构型还是S构型;能够读出“95% ee”,却不一定理解这种立体选择性对应的结构差异。
更重要的是,Think模式几乎无法改善结构识别成绩。同一组模型在机理推理任务上获得明显提升,在结构识别任务上却原地踏步。简单来说就是:推理能补“不理解”的缺,却补不了“看不清”的缺。
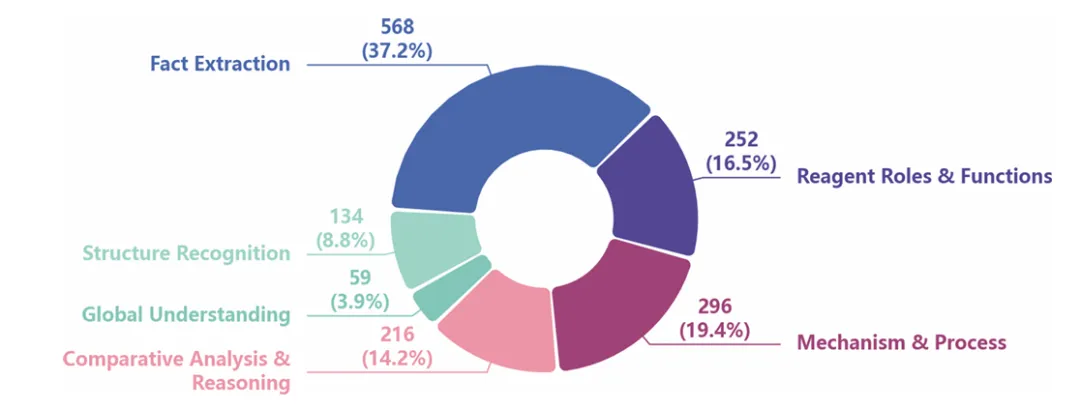
图3:不同题型表现对比