年初就在盼着去年封神的DeepSeek,今天V4它来了!
1
先说跟的一个数字:100万。
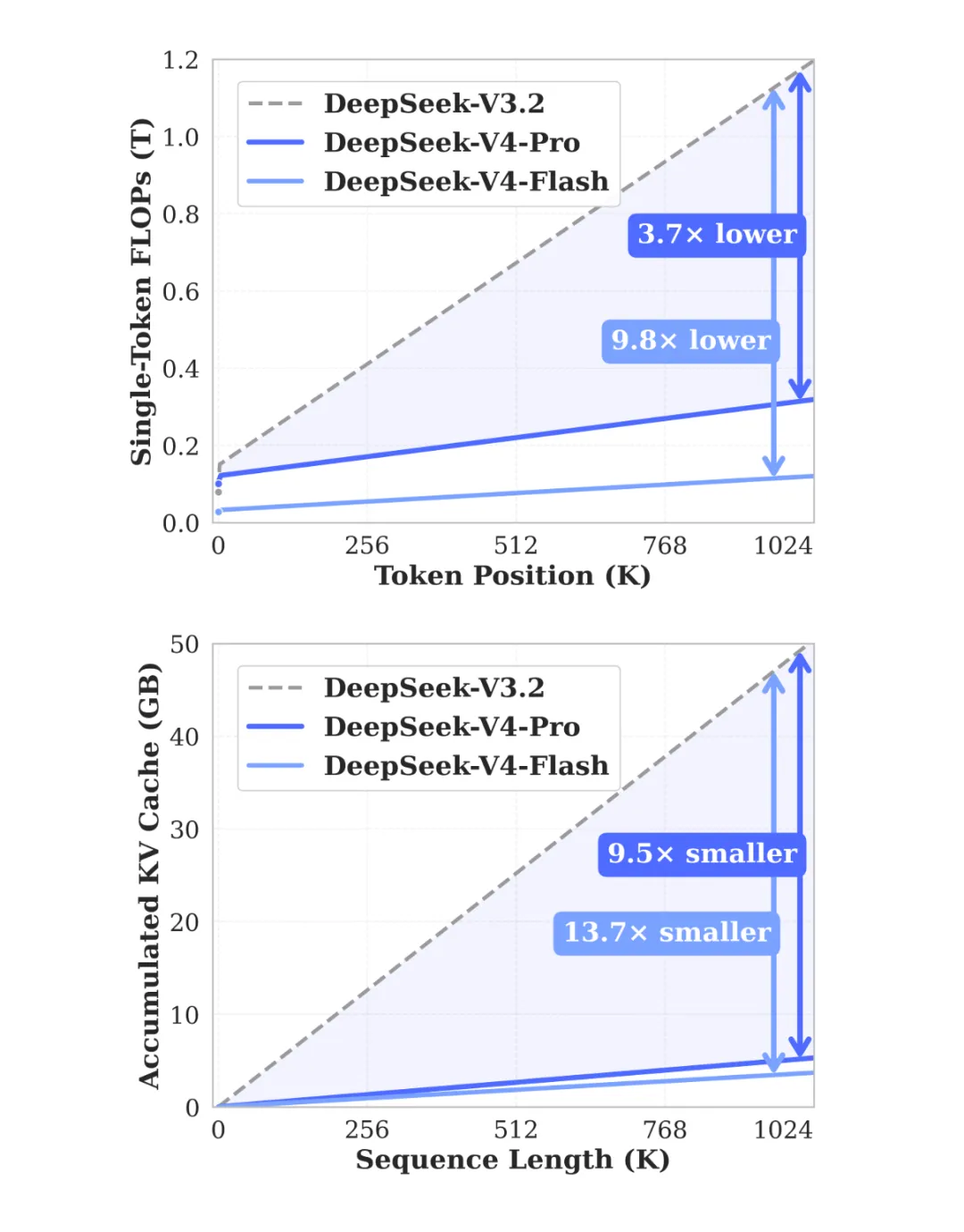
V3.2的上下文窗口是128K token,4直接拉到100万翻了将近8倍。
100万token大约等于80万字中文,拿来做参照:刘慈欣的《三体》三部曲加起来大概88万字,一次性丢进去,还剩点余量。
这改变的不是「能读多长的文章」,而是工作方式。
以前用大模型处理长文档,核心工作量是「怎么把大象分成小块装进冰箱」,现在冰箱变成了仓库。
但仓库大不等于找东西快 DeepSeek自己公布的数据显示,V4在100万token长度下的检索准确率MRCR 1M拿了83.5分,Claude Opus 4.6是92.9。能装了,找得准不准还有差距。
同样的显卡和显存,能扛的请求量翻了好几倍。
2
DeepSeek一直在编程这条线上死磕,V4交出了目前最好的答卷。
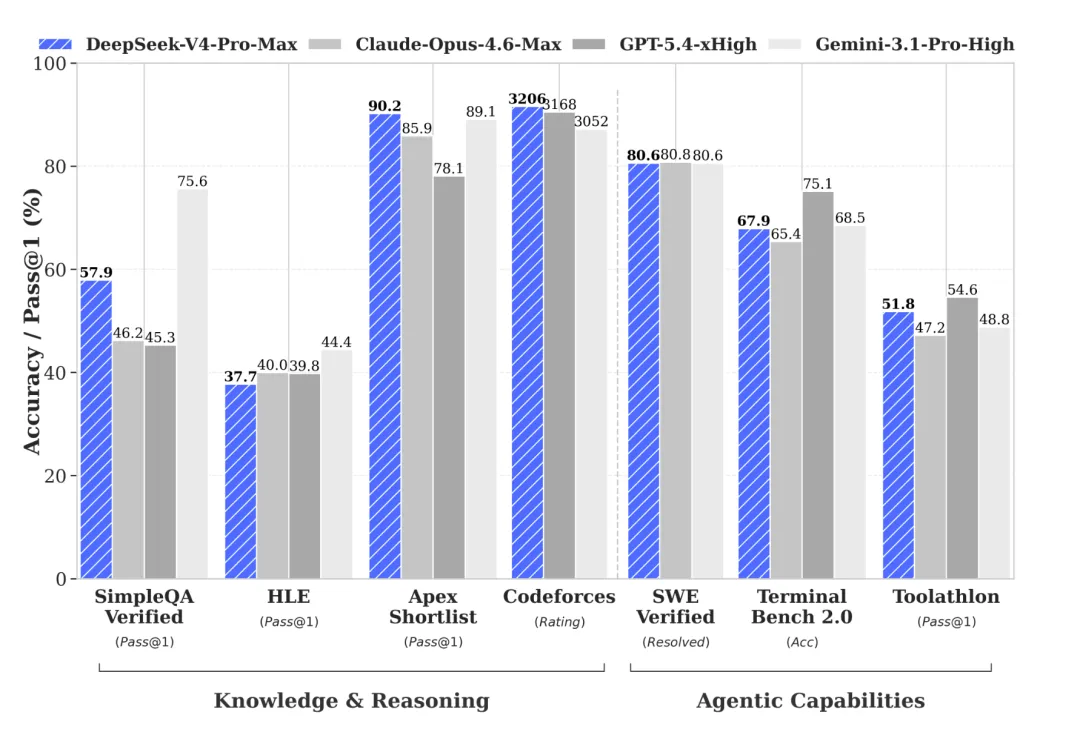
Codeforces竞赛评分3206而GPT-5.4是3168,这是开源模型第一次在竞赛级编程上站到了闭源模型前面。
SWE-bench Verified修真实GitHub issue的测试V4-Pro拿了80.6,Claude Opus 4.6是80.8,两者咬在一起。
这些数字放在一年前,任何一个开源模型都摸不到边。
但V4的短板也很明显:
HLE测试和世界知识检索SimpleQA这两项V4分别只拿37.7和57.9。
论写代码它是尖子生,但百科知识这方面它还得补课。
如果说Claude是全科学霸,V4更像是理科偏科生,数学和编程拿满分,历史地理还在及格线晃。
3
V4这次上了两个模型,Pro和Flash。
V4-Pro1.6万亿总参数,每次推理激活49B,适合干复杂推理的任务。产品端叫「专家模式」,支持深度思考和搜索。
V4-Flash284B总参数,激活13B轻快便宜。产品端叫「快速模式」,日常聊天和简单任务用这个。
API价格是V4最有杀伤力的部分。
Pro输出token 0.28/百万。Claude Opus 4.6的输出价格是$75/百万,Pro便宜了20倍,Flash便宜了260倍。
如果你在跑批量任务、做自动化流程、搞内容生产线,这个价差会直接砍掉你的成本。
论性能跟闭源第一梯队咬在一起,论价格差了一到两个数量级。
这是DeepSeek一贯的打法:用价格把护城河里的水抽干。
4
V4从R1之后隔了这么久,不是因为模型没训好。
根据多家媒体报道,DeepSeek在过去一年多里做了一件极其吃力的事:
把整个技术底座从英伟达CUDA框架迁移到华为昇腾CANN架构,V4完全运行在华为芯片上。
DeepSeek没给英伟达和AMD提前适配的机会,早期访问权限只开放给了华为和寒武纪。
最后的结果就是V4在昇腾上的推理速度比初期版本提升了35倍,部署成本大约是英伟达方案的三分之一。
黄仁勋在最近的采访里直说了,如果前沿模型能在国产芯片上跑出竞争力,英伟达的生态护城河会被动摇。
对普通用户来说,你打开DeepSeek网页或者调API,感知不到背后跑的是哪家芯片。
但这件事的长期影响比V4模型本身可能更大:
它给AI产业链打了一个样板,证明万亿参数模型可以不依赖英伟达。
5
V4选在GPT-5.5发布的同一天上线。一个开源免费,一个闭源付费。同日发布,新闻周期对半分。
V4的官方措辞很克制,叫Preview预览版。
如果说R1是DeepSeek对全世界喊的那一嗓子,V4更像是它低着头做完一道难题之后,把卷子默默翻过来放在桌上。
这份试卷的名字的名字叫:不用英伟达,也能跑万亿参数。
至于考试成绩单,阅卷人还在路上。