★ 关注小卫,了解【#公卫考研#预防医学#公共卫生考研#预防医学考研#353卫生综合】更多资讯~
1
前言
统计方法选择的第一步,不是计算,而是识别——识别资料类型,识别设计类型,识别分析目的。2026年浙江大学这道真题,以”新生儿血清总胆红素”的三组数据为素材,用四个层层递进的问题,从”这是什么资料”到”这是什么设计”,从”怎么描述”到”怎么分析”,完整呈现了统计方法选择的思维链条。
这道题看似简单,却是所有复杂分析的基础。很多考生急于计算t值或F值,却在第一步”资料类型判断”上出错——把”有序分类”当作”定量资料”,把”完全随机设计”当作”配对设计”,导致后续全错。今天,我们把这套“识别→描述→推断”的基础功,练到精准无误!
2
真题再现
1、某年某地某医生以案例30名有代表性的新生儿血清总胆红素值(mg/dl)的数据见表,每组10名。
(1)该资料属于什么类型的资料?(2分)
(2)该研究设计类型是什么?(2分)
(3)该选择什么指标来描述3组新生儿血清总胆红素值并进行评价?(请指出评价方法和公式形式,但不需要计算)(2分)
(4)如果需要推断新生儿肝炎与胆红素之间相关关系及相关程度,需要采用什么分析方法?请写出方法名称及选择方法的理由。(注:不需要具体计算)(2分)
3
满分答案
(1)资料类型判断
结论:定量资料(数值变量资料/计量资料)
判断依据:
排除其他类型:-❌计数资料(如阳性/阴性人数)-❌等级资料(虽然分组有顺序,但测量值为具体数值)
💡 评分关键:答出”定量资料”或”计量资料”得2分;答”数值变量”也可得分。
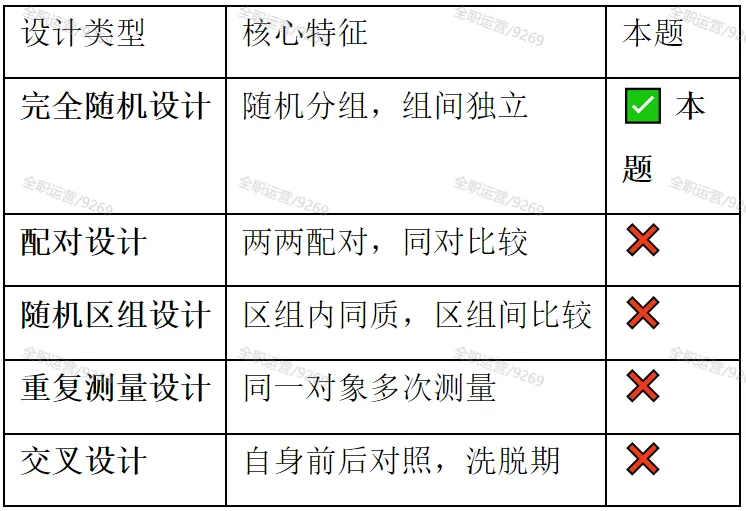
(2)研究设计类型判断
结论:完全随机设计(成组设计/单因素设计)
排除其他设计:-❌配对设计(无配对关系)- ❌随机区组设计(无区组因素)-❌重复测量设计(无同一对象多次测量)
💡 评分关键:答出”完全随机设计”或”成组设计”得2分。
(3)统计描述与组间比较方法
① 描述指标:均数±标准差(x±s)
选择理由:-定量资料,数据分布近似对称(无极端异常值)-均数描述集中趋势,标准差描述离散趋势
② 组间比较方法:完全随机设计的单因素方差分析(One-way ANOVA)
公式形式:
其中:-ν组间=k−1=3−1=2-ν组内=N−k=30−3=27
💡 评分关键:描述指标正确得1分;方差分析方法正确得1分;公式正确得1分。
(4)相关分析方法选择
结论:应采用Spearman等级相关分析
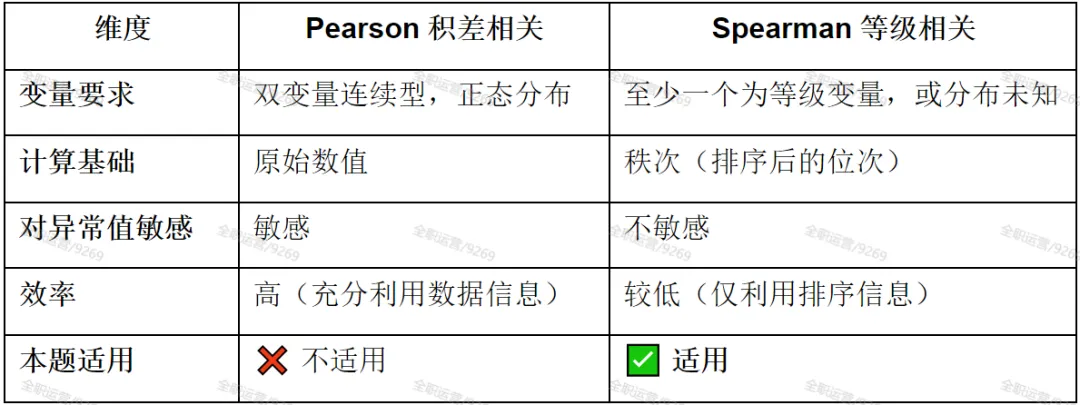
理由:肝炎分组为有序分类资料(等级资料):正常→轻度→重度有等级顺序,分析目的是判断等级与血清胆红素数值之间的相关方向与密切程度;不满足 Pearson 积差相关要求的双变量正态分布条件,因此选用Spearman 等级相关。
4
核心知识点复习
知识点1:研究设计类型的识别矩阵
知识点2:统计方法选择的决策树
第一步:识别资料类型
↓ 定量资料
第二步:识别设计类型
↓ 完全随机设计,多组比较
第三步:选择描述指标
↓ 均数±标准差(正态)或中位数(四分位数)(偏态)
第四步:选择推断方法
↓ 单因素方差分析(多组均数比较)
第五步:识别相关变量类型
↓ 等级变量 + 连续变量 → Spearman等级相关
知识点3:Pearson相关vsSpearman相关的辨析
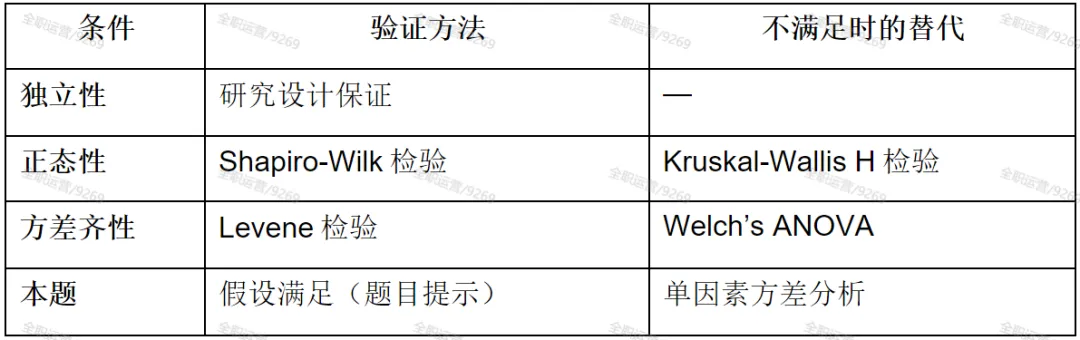
知识点4:方差分析的前提条件与替代方案
5
秒杀口诀
✔ 资料类型判断口诀
“有单位能运算,定量资料无疑问;分类型无单位,计数等级要区分”
✔ 设计类型判断口诀
“随机分组独立比,完全随机来设计;配对区组重复测,特征不同要辨清”
✔ 统计方法选择口诀
“定量资料均数标,多组比较方差找;等级连续相关问,Spearman来Pearson退”
✔ Pearson vs Spearman口诀
“Pearson要正态连续双,Spearman等级偏态扛;一个高效一个稳,选对方法不慌张”
6
系列收官:卫生统计学真题拆解全景回顾
系列核心收获: - ✅ 掌握资料类型→设计类型→描述指标→推断方法的完整决策链 - ✅ 精通t检验、方差分析、相关回归、Logistic回归四大核心技术 - ✅ 理解生态学谬误、相关≠因果、模型选择等高级概念 - ✅ 建立“识别→描述→推断→解释”的统计思维框架
感谢陪伴,卫生统计学真题拆解系列正式收官!
⭐ 点击查看:往期【真题拆解】系列推文
关注本号,持续更新2026年公共卫生考研干货,
助你353专业课高分上岸!
抢跑上岸 卫灿助你
点击查看 近期热门
给小卫点个赞吧ヾ(◍°∇°◍)ノ゙!