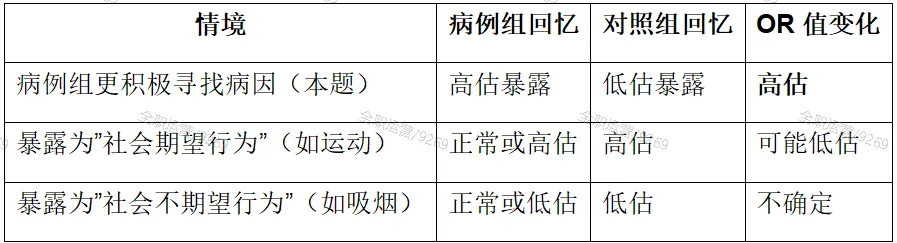
一、研究对象选择方面:核心控制入院率偏倚,提升代表性与可比性
①病例组的完善策略 。
A扩大医院选择范围:在原有北京两家三甲医院基础上,纳入不同级别、不同种类的医疗机构,包括基层医院、社区医院、肿瘤专科医院,避免单一三甲医院患者特征的局限性;
b 严格坚持新发病例入组:本研究已选择病理诊断的连续新发胃癌患者,需继续保持该标准,排除现患病例,同时纳入不同病程的早、中、晚期胃癌患者,进一步减少选择偏倚。
②对照组的完善策略
a 优先选择社区人群对照:尽可能在病例组所在社区中选择对照,通过随机抽样获得与病例组同地域、同年龄性别构成的社区健康人群,保证对照的人群代表性,从根源上减少入院率偏倚;
b若采用医院对照,需满足多科室、多病种要求:在与病例相同的多个医院中,从多个科室、多病种的患者中选择对照,同时排除与饮茶暴露因素相关的病种患者作为对照,避免入院率差异带来的偏倚;
c 增加匹配因素:在原有年龄、性别匹配的基础上,增加社会经济状况、就医习惯、文化程度等匹配因素,保证病例组与对照组的可比性。
③整体抽样策略:采用多中心抽样,纳入北京及周边地区的代表性医疗机构,扩大病例与对照的样本来源,提升研究结果的外推性。
二、资料收集方面:核心控制回忆偏倚与调查偏倚,保证信息准确性与统一性
①控制回忆偏倚的策略:
a充分利用客观记录资料:收集研究对象的饮食消费记录、体检报告、日常日记等客观资料,验证饮茶暴露史的真实性,减少主观回忆的误差;
b设计标准化调查问卷:将饮茶暴露指标量化、细化,如饮茶年限、每周频率、饮用量、茶类等,采用选项式答题方式,规范提问方式,减少回忆模糊性;
c借助调查技巧辅助核实:对饮茶暴露史模糊的研究对象,可通过其家属、亲友进行信息核实,提升暴露信息的完整性。
②控制调查偏倚的策略:
a统一调查员培训与调查标准:对所有调查员进行标准化培训,明确饮茶暴露的定义、调查流程与提问方式,考核合格后方可开展调查,保证不同调查员的调查标准一致;
b采用盲法调查:调查员收集暴露信息时,不知晓研究对象的病例/对照分组状态,将分组信息与暴露调查分离,避免调查员的主观倾向影响调查结果;
c统一调查环境与条件:对病例组和对照组采用相同的调查环境、调查方式,尽可能使用量化或等级化的客观指标记录饮茶暴露信息,减少人为测量误差; d做好调查质量控制:设置质控员,对完成的调查问卷进行≥20%的随机抽查,通过电话回访核实暴露信息,对不合格问卷重新调查,保证调查质量。
③提升资料收集的客观性:向研究对象明确调查目的,取得信任与合作,减少因不配合导致的报告偏倚。