——如阅读体验不佳,可转为横屏阅读;如微信无法横屏,可尝试文末方法。
插入排序
直接插入排序
基本思想:在有序表中顺序寻找插入点。(顺序查找时从后往前找,可①当待排记录序列已有序时,其时间复杂度可由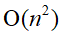 提高至
提高至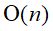 ;②比较和移动可同步进行。)
;②比较和移动可同步进行。)
折半插入排序
基本思想:在有序表中折半查找插入点。
希尔排序
基本思想:当待排记录序列按关键字基本有序时,直接插入排序的效率可大大提高。希尔排序先将整个待排序的记录序列分割为若干子序列分别进行直接插入排序,在整个序列“基本有序”时,再对整个序列进行一次直接插入排序。
实现方法:
缩小增量排序中,对于一趟(按同一增量)排序,各增量子序列的排序并列(同步)进行。每趟(增量值不为1时)对于每个子序列均是直接插入排序;最后一趟(增量值为1时)对整个序列进行直接插入排序。
增量序列的取法:1)增量序列中的值没有除1之外的公因子;且2)最后一个增量值为1。
交换排序
冒泡排序
基本思想:若相邻两个记录的关键字逆序,则交换这两个记录,每趟可从无序序列中选出关键字最大(冒泡)的记录插入有序序列的尾部。
快速排序
基本思想:通过一趟排序将待排序记录分割成独立的两部分,其中一部分记录的关键字均比另一部分记录的关键字小,再分别对这两部分记录进行排序,以达到整个序列有序。(当待排记录序列按关键字基本有序时,快速排序退化为冒泡排序。)
实现方法:
(1)一趟快速排序:将待排序列的第一个记录作枢轴记录,从待排序列的两端交替地向中间扫描,将比枢轴记录关键字小的记录移到低端,将比枢轴记录关键字大的记录移到高端。具体做法是设两个指针low和high,它们的初值分别为low(待排序列的头)和high(待排序列的尾),设枢轴记录的关键字为pivotkey,则1)首先从high所指位置向前搜索找到第一个关键字小于pivotkey的记录和枢轴记录互相交换;2)然后从low所指位置向后搜索找到第一个关键字大于pivotkey的记录和枢轴记录互相交换;重复以上两步直至指针low=high为止。(在一趟排序中,每次被移动的记录的原位置是枢轴记录的新的临时位置,只有在一趟快速排序结束时,即low=high的位置才是枢轴记录的最后位置,因而在每趟排序中先将枢轴记录暂时放在r[0]的位置上,排序过程中只做r[low]和r[high]的单向移动,直至一趟排序结束后再将枢轴记录移至low=high的位置上。在一趟排序中,每次轴枢记录的新的临时位置将所有记录分为两部分,一部分A中的所有记录的关键字都大于(或小于)或等于轴枢记录的关键字;另一部分B中只有远离轴枢记录新位置的那些记录的关键字都小于(或大于)或等于轴枢记录的关键字,而靠近轴枢记录新位置的那些记录的关键字与轴枢记录的关键字的大小关系不一致,此时需进行B中与轴枢记录的关键字的大小关系不一致的那些记录的关键字与轴枢记录的关键字的比较。)
(2)整个快速排序的过程可递归进行,递归结束的条件是待排序序列中只有一个记录,否则进行一趟快速排序后再分别对分割所得的两个子序列进行快速排序。
枢轴记录的选取法则为“三者取中”,即比较记录L.r[s].key、L.r[t].key和L.r[(s+t)/2].key,取三者中其关键字取中值的记录为枢轴记录,可将该记录与L.r[s]互换实现将待排序列的第一个记录作枢轴记录。
选择排序
简单选择排序
基本思想:每次使用顺序比较(相邻元素逐一比较)的方法从待排序列中选出最小或最大元素作为有序序列中的新元素。
实现方法:
(1)一趟简单选择排序:第i趟通过n-i次关键字间的比较,从n-i+1个记录中选出关键字最小的记录,并和第i个记录交换之(该交换操作是造成不稳定的原因,可能引起第i个记录和在它之后与它的关键字相等的某个记录的之间的相对次序发生变化)。
(2)进行n-1趟简单选择排序。
堆排序
基本思想:堆顶元素是堆中的最大或最小元素,每次选取堆顶元素作为有序序列中的新元素,并对余下的元素调整为一个新堆,反复操作便可得到待排序列的有序序列。
堆:1)从根(堆顶)至叶(堆端)的路径上的各元素之间均有序;2)处于同一层次上的各元素之间的大小关系不定,即父子链上的各元素之间有序,兄弟“链”上的各元素之间无序。
堆调整时,每次从父和两子(兄弟)三者中选最大者作为新的父,并沿新父原来所引导的堆调整(因为未受影响的分枝之前满足堆的定义,无需调整),最终的调整轨迹是某一条从根至叶的路径。调整时不需回溯,因下面的(根、左右子)结构符合堆的定义,待调元素先和根调整,然后再和根的左(或右)子调整,则两次调整后根与左(右)子之间仍是原来的关系(父子),仍符合堆的定义。
堆建立的过程是反复筛选(即以当前待筛选元素为堆顶的堆的自堆顶至叶子的堆调整)的过程,若将无序序列看作是完全二叉树,则最后一个非终端结点是第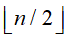 个元素,因此“筛选”只需从第
个元素,因此“筛选”只需从第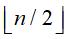 个结点(该结点之后的结点均无子结点,无需判断堆的定义)开始反向逐个递进,又每次筛选元素的左右孩子所引导的元素均已符合堆的定义(因是反向进行的),故每次“筛选”是一次以当前待筛选元素为堆顶的堆的堆调整。
个结点(该结点之后的结点均无子结点,无需判断堆的定义)开始反向逐个递进,又每次筛选元素的左右孩子所引导的元素均已符合堆的定义(因是反向进行的),故每次“筛选”是一次以当前待筛选元素为堆顶的堆的堆调整。
堆调整:从堆顶起,自上而下对某一条从堆顶至堆端的路径上的元素所引导的堆进行调整。
堆建立:从第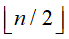 个元素起,自下而上对每一个元素所引导的堆进行堆调整。
个元素起,自下而上对每一个元素所引导的堆进行堆调整。
归并排序
2-路归并排序
基本思想:将两个有序表合并为一个有序表。
实现方法:每一趟将一维数组中前后相邻的两个有序序列合并为一个有序序列,共需[log2n](第1趟待归并的序列个数为n,第2趟待归并的序列个数为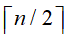 ,第i趟待归并的序列个数为
,第i趟待归并的序列个数为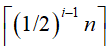 ,第t趟即最后一趟待归并的序列个数为
,第t趟即最后一趟待归并的序列个数为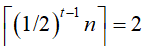 ,即
,即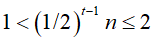 ,故
,故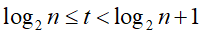 ,即
,即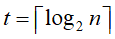 )趟完成整个序列的归并排序。
)趟完成整个序列的归并排序。
基数排序
基本思想:借助多关键字排序的思想对单逻辑关键字进行排序。
实现方法:
(1)最高位优先MSD法:每次选择一个关键字分量作为排序依据对当前的各个子序列分别进行内部排序并分割。(关键操作为“排序”和“分割”,化整为零)
具体做法:①首先以较高位关键字分量为排序依据,对当前各个子序列分别进行内部排序,然后将内部有序的各个子序列进一步分割为若干子序列(当前作为排序依据的关键字分量相同的关键字处于同一子序列);②选择次高位关键字分量为排序依据,对当前的各个子序列进行内部排序并分割;③重复②直至使用最低位关键字分量作为排序依据完成排序。(初始状态为,最高位关键字分量为较高位关键字分量,整个序列为一个子序列。)
(2)最低位优先LSD法:对每个关键字分量都是整个序列参加排序,对关键字分量Ki(0≤i≤d-2,K0为最主位关键字分量,Kd-1为最次位关键字分量)进行排序时,只能使用稳定的排序方法(因为整个序列已按关键字分量Ki+1有序)。(关键操作为“分配”和“收集”,化零为整)
具体做法:①第一趟分配对最次位关键字分量进行,将n个记录分配到r(r为各个关键字分量的取值范围,即基)个队列中,每个队列中的记录的最次位关键字相同;②第一趟收集是将r个队列中每个非空队列的队尾记录的指针域指向其下一个非空队列的队头记录(可保证排序的稳定性);对待排序列执行d(d为逻辑关键字中关键字的个数)趟上述分配和收集操作。基数排序的时间复杂度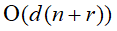 中的n表示每趟中分配操作的复杂度,r表示每趟中收集操作的复杂度,d表示总趟数。
中的n表示每趟中分配操作的复杂度,r表示每趟中收集操作的复杂度,d表示总趟数。
文章合集:
点击下方公众号主页,关注以阅读更多文章
——可选择“【右上角···】→【在浏览器中打开】”进行横屏阅读。

