识别财报、试卷、合同绝了!几大开源 OCR 超强工具,你值得拥有
- 2026-06-17 15:34:31
对比当前几大开源 OCR 超强工具
日常办公、资料整理、图片转文字场景中,OCR工具的出镜频率居高不下,谁还没被“手动打字录入图片文字”逼疯过?市面上开源OCR方案五花八门,适配场景、识别精度、部署难度差得不少——有的主打中文精准识别,有的胜在轻量化开箱即用,有的靠大厂背书稳定性拉满。

一、前十大大开源OCR工具对比
地址可直接复制,一眼看清各工具底细:
二、主要介绍几个简单使用+功能亮点
每款工具都附「一键安装命令」,复制就能跑,不用瞎折腾,重点讲“好用在哪、适合谁”,避开专业术语坑。
●1. Tesseract OCR:开源OCR老大哥,稳就一个字
作为开源OCR圈的“老前辈”,Star数直接拉满56.3k+,生态成熟到离谱,虽然颜值一般,但耐造、免费、无套路。
安装方式(全系统适配)
macOS:打开终端,输入
brew install tesseract(前提是装了brew,没装的先搜“brew安装教程”,两步搞定)Windows:去GitHub地址下载安装包,一路下一步,记得勾选“配置环境变量”,不然终端找不到命令
Linux:终端输入
apt install tesseract-ocr,等待自动安装完成
功能亮点
支持100+语言,不管是中文、英文,还是小众语种,装个语言包就能识别,兼容性拉满
主打印刷体识别,清晰的文档、图片文字,识别准确率不低,还能输出txt、pdf等多种格式
可搭配ImageMagick做图片预处理(比如去模糊、调亮度),能小幅提升识别精度
支持命令行批量处理,适合写脚本自动化操作,比如批量转几十张图片为文字
基础使用(终端直接敲)
tesseract 图片路径 输出文件名 -l 语言代码# 示例:识别当前目录的test.png,输出为result.txt,用中文识别tesseract test.png result -l chi_sim●2. PaddleOCR-VL-1.5:中文党福音,复杂场景扛把子
百度飞桨出品,Star数38.6k+,算是目前中文OCR里的“顶流选手”,专门优化中文识别,复杂场景比其他工具更能打。
安装方式(极简pip安装)
# 先装依赖,再装核心包,复制一行行运行pip install paddlepaddlepip install paddleocr功能亮点
中文识别精度拉满,支持竖排文字、印章、手写体、票据、表格,甚至模糊的图片也能识别
自带检测+识别+方向分类三合一能力,不用额外配置,就能处理倾斜、倒置的图片
可部署为HTTP API,轻松对接小程序、后台系统,适合企业级轻量集成
有GUI工具,没代码基础的办公党,双击打开就能用,不用敲命令
基础使用(终端/无代码均可)
# 终端命令:识别图片,自动矫正方向paddleocr --image_dir 图片路径 --use_angle_cls true# 示例:识别test.jpg,输出识别结果paddleocr --image_dir test.jpg --use_angle_cls true无代码用法:安装后,终端输入 paddleocr --gui,打开图形界面,拖入图片就能识别。
●3. MinerU 2.5:轻量化黑马,新手零门槛
OpenDataLab出品,Star数4.8k+,主打“轻量化、易上手”,不用复杂配置,装完就能用,适合临时应急、日常办公。

安装方式(pip一键搞定)
pip install mineru功能亮点
安装简单,依赖项少,不会出现“装半天装不上”的情况,新手也能一次成功
识别速度快,小图片几秒就能出结果,支持批量识别,日常办公完全够用
支持多格式导出,识别结果可保存为txt、md、pdf,方便后续编辑
界面简洁,操作简单,不用记复杂命令,拖入图片就能识别,办公党友好
基础使用(两种方式任选)
终端命令:
mineru 图片路径 -o 输出路径图形界面:终端输入
mineru --gui,打开后拖入图片,点击“识别”即可
●4. DeepSeek-OCR 2:高精度选手,复杂背景也能打
DeepSeek出品,Star数2.7k+,主打“高精度识别”,针对复杂背景、模糊文字做了优化,适合对识别精度有要求的场景。
安装方式(git克隆+依赖安装)
# 先克隆项目到本地git clone https://github.com/deepseek-ai/DeepSeek-OCR-2# 进入项目目录cd DeepSeek-OCR-2# 安装依赖pip install -r requirements.txt功能亮点
印刷体识别精度高,即使图片有轻微模糊、阴影、噪点,也能准确识别文字
支持批量处理,可一次性识别多个文件夹的图片,适合大量资料整理
支持自定义模型微调,可根据自身需求,优化特定场景的识别效果
输出结果清晰,可标注文字位置,方便后续二次编辑
基础使用(脚本调用)
from deepseek_ocr import DeepSeekOCR# 初始化识别器ocr = DeepSeekOCR()# 识别图片result = ocr.recognize("图片路径")# 打印识别结果print(result)●5. HunyuanOCR:腾讯大厂款,稳定性拉满
腾讯混元生态出品,Star数1.9k+,背靠大厂,稳定性有保障,专门适配中文办公场景,表格、公式识别是亮点。
安装方式(git克隆+依赖安装)
# 克隆项目git clone https://github.com/Tencent/HunyuanOCR# 进入项目目录cd HunyuanOCR# 安装依赖pip install -r requirements.txt功能亮点
腾讯官方背书,代码规范,bug少,部署后稳定性强,适合企业级使用
支持表格、公式、图片文字一体化识别,办公党整理报表、论文时特别实用
中文识别优化到位,竖排、繁体中文也能准确识别,适配更多场景
支持批量导出,识别结果可直接保存为Excel、txt,不用手动复制粘贴
基础使用(终端命令)
# 识别图片,指定输出格式为Excel(表格识别专用)python run_ocr.py --image_path 图片路径 --output_format excel# 普通文字识别,输出为txtpython run_ocr.py --image_path 图片路径 --output_format txt三、选型建议:按场景快速匹配
不用纠结哪个最好,按自己的需求选,效率最高:
日常办公、临时识别、新手零门槛:选 MinerU 2.5(安装简单,操作便捷)
中文复杂场景(证件、票据、竖排文字):选 PaddleOCR-VL-1.5(中文优化最到位)
高精度印刷体、批量处理、研究场景:选 DeepSeek-OCR 2(精度拉满)
企业级使用、表格/公式识别、追求稳定:选 HunyuanOCR(腾讯背书,靠谱)
多语言识别、自动化脚本、小众语种:选 Tesseract OCR(生态成熟,兼容性强)
以上5款开源OCR工具,覆盖了从新手办公到企业部署、从简单识别到高精度需求的全场景,全部免费开源,不用依赖付费接口,复制GitHub地址就能获取源码,安装也都简化到“复制命令”就能搞定。
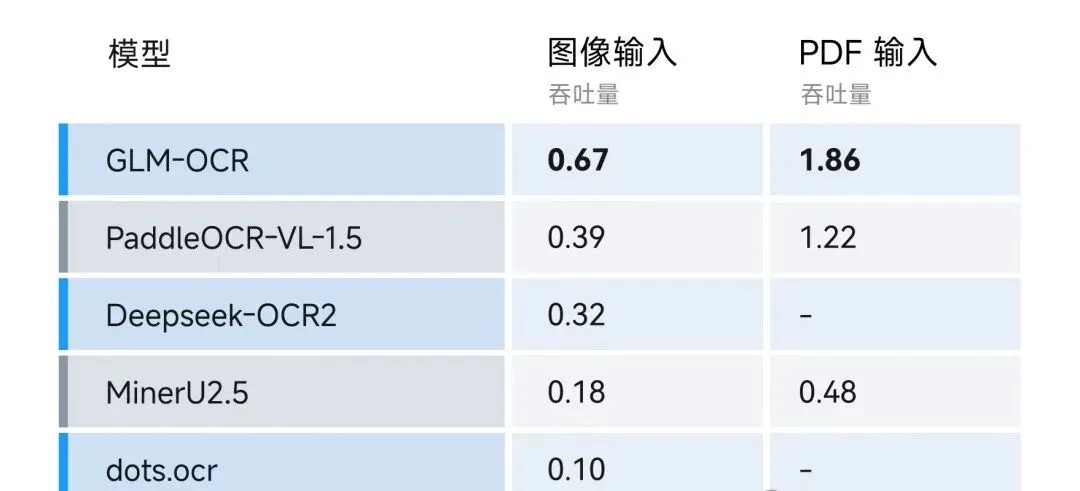
其他开源排行
其实开源OCR的核心就是“适配场景”——不用追求最复杂的,选最贴合自己需求的,就能省出大把手动打字的时间。
#开源OCR #OCR工具推荐 #文字识别工具 #PaddleOCR #MinerU #DeepSeekOCR #HunyuanOCR #Tesseract #技术教程 #办公效率工具

牛逼!腾讯火速上线 Skill仓库,轻松一键使用,盘点几个神级 Skill 网站
1300个Codex资源...给需要的有缘人,刷出Free额度就能用...
OpenClaw安装免费!上门卸载要299!这只“龙虾”的坑竟这么多|附详细卸载教程
眼花缭乱!国内阿里、腾讯、小米大厂小龙虾"Claw"一网打尽!小白该怎么选?



